연결 리스트(Linked List)
그 크기가 동적인 자료구조로 노드(자료구조를 구성하는 요소)의 연결로 이루어진 자료 구조
첫 번째 노드는 'HEAD'라고 부르며, 마지막 노드는 'TAIL'이라고 부르며, TAIL 노드의 레퍼런스는 null이다.
각 노드는 (1) 현재 데이터, (2) 다음 데이터의 주소(레퍼런스)를 지니며 다른 데이터의 이동 없이 중간에 삽입이나 삭제가 가능하다.
그리고 길이 제한이 없다.
연결 리스트에는 두 가지의 종류가 존재한다.
단일 연결 리스트(Singly-Linked List): 단일 연결 리스트는 각 노드에 자료 공간과 한 개의 포인터 공간이 있고, 각 노드의 포인터는 다음 노드를 가리킨다. 단일 연결 리스트에서 각 노드는 자신의 이전 노드를 알 수 없다.
이중 연결 리스트(Doubly-Linked List): 이중 연결 리스트의 구조는 단일 연결 리스트와 비슷하지만, 포인터 공간이 두 개가 있고 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킨다.

[property] : head / size
[method]
addToTail(value) : 주어진 값을 연결 리스트의 끝에 추가
remove(value) : 주어진 값을 찾아서 연결을 해제(삭제)
getNodeAt(index) : 주어진 인덱스의 노드를 찾아서 반환(값이 아니라 노드), 해당 인덱스에 노드가 없다면 undefined를 반환
contains(value) : 연결리스트에 주어진 값을 가지는 노드의 존재 여부를 반환한다.
indexOf(value) : 주어진 값의 인덱스를 반환한다. 없을 경우 -1을 반환한다.
해쉬테이블(Hash Table)
키, 값 쌍을 저장하고 있는 자료 구조
해쉬 테이블은 키를 저장할 때에 메모리 공간을 덜 사용할 수 있도록, 키를 "해쉬 함수"(Hash function)라는 함수를 통해 특정 숫자 값의 인덱스로 변환한다. 해쉬 테이블은 필요할 때에만 메모리 크기를 늘리고 가능한 작은 크기를 유지한다.
해싱이란?
대부분의 탐색 방법들은 탐색 키를 저장된 키 값과 반복적으로 비교하면서 탐색을 원하는 항목에 접근하지만 해싱은 키 값에 직접 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근한다. 이렇게 키 값의 연산에 의해 직접 접근이 가능한 구조를 해쉬 테이블(hash table)이라 부르고, 해쉬 테이블을 이용한 탐색을 해싱(hashing)이라 한다.
해쉬 함수의 특징에는 3가지가 존재하는데 역상 저항성(?), 제2 역상 저항성(?), 충돌 저항성(?) 막상 이해를 하면 별거 아닌 내용이지만 처음에 맞닥드렸을땐 이게 뭔가 지레 겁먹었던 것 같다. 해쉬 함수 특징의 3가지를 쉽게 나열하면 아래와 같다.
첫째, 결과 값이 중복될 가능성이 거의 없다.
둘째, 입력 값을 알 수 없다.
셋째, 결과 값을 알려주고 입력 값을 찾을 수 있는 특별한 공식이 없다.

모든 것에는 장 단점이 있는 것처럼 해쉬 테이블에도 단점들이 존재한다. 해쉬 충돌이 큰 단점인데 이는 해쉬 함수의 알고리즘이 데이터 분류에 적합하지 않은 경우, 복수의 데이터가 같은 인덱스로 분류되는 것을 말한다. 이 경우 검색 속도가 빠르다는 장점이 약해진다.
여기서 새로운 개념 3가지를 정의하고 가자.
- storage : 해쉬 테이블의 그 "테이블"로 데이터들을 저장하는 공간이고, 배열이다.
- bucket : 데이터가 들어갈 공간을 말하는데 이 버켓은 인덱스에서 담겨 있고, 데이터 하나마다 버켓 하나가 들어간다.
- tuple : 데이터들을 담고 있는 곳을 말하며 이 데이터는 수정 혹은 추가, 삭제할 수가 없기 때문에 tuple과 같은 첨삭이 불가한 읽기 전용이다.
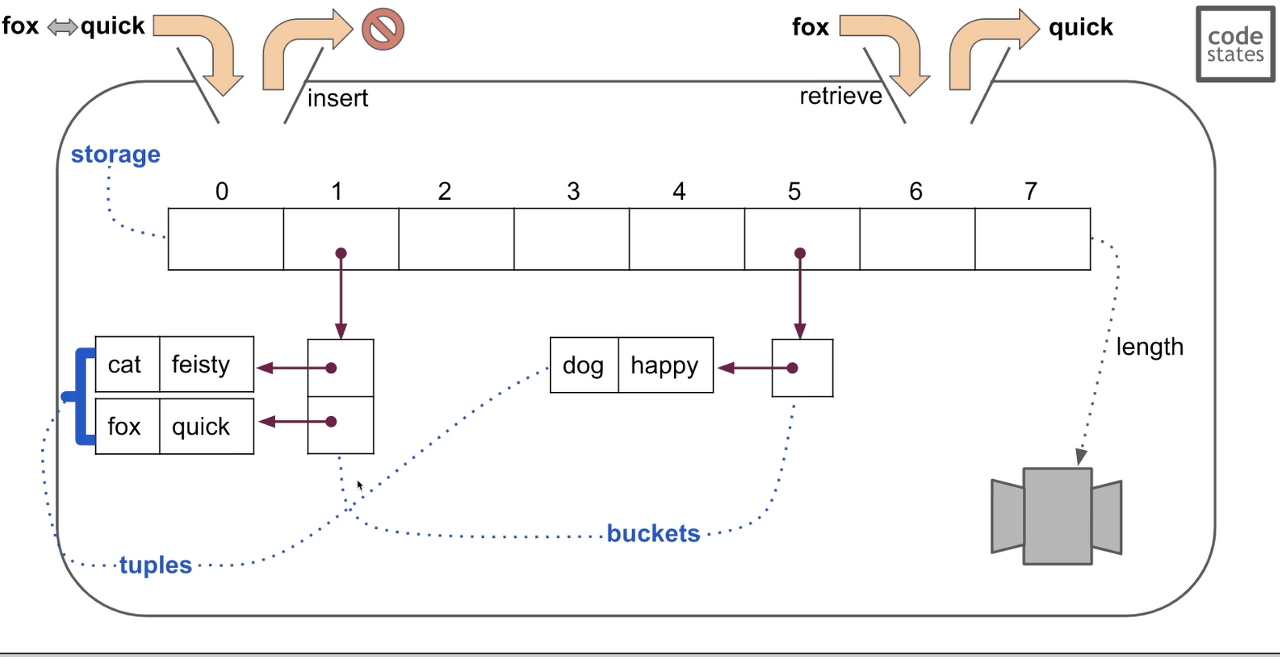
앞서 말한 해쉬 충돌시에 충돌이 생기면 충돌한 데이터 별로 bucket이 생성되고 각 데이터의 key, value가 tuple에 저장된다.
이러한 해쉬 충돌은 어떻게 하면 안 나게 할 수 있을까? 웃기지만 제일 최선의 방법은 해쉬 함수를 잘 짜는 것! 이 이러한 걱정을 하지 않는 방법이 될 것이다.
해쉬 충돌을 처리하는 방법은 다양하지만 이 방법을 크게 두 가지 용어로 분류하는데 크게 Open addressing과 Close addressing으로 분류한다.
1. Open addressing : 해쉬 값과 실제 저장된 위치가 다를 수 있다. 즉 충돌이 일어나게 되면 다른 인덱스에 저장하도록 조정한다.
선형 탐사 : 기존에 3번에 저장되어 있는 데이터가 있는데 다른 데이터 또한 3번에 배정된다면 3번은 이미 차지하고 있으므로 다음 칸이 비어 있는지를 검사한다. 4번칸이 비어 있으므로 44번 칸에다가 배정한다.
제곱 탐사 : 고정 폭으로 이동하는 선형 탐사와 달리 그 폭이 제곱수로 늘어난다는 특징이 있다. 예컨대 임의의 키값에 해당하는 데이터에 액세스 할 때 충돌이 일어나면 1^2칸을 옮긴다. 여기에서도 충돌이 일어나면 이번엔 2^2칸, 그 다음엔 3^2칸 옮기는 식이다.
이중 해쉬해쉬 함수를 2개를 두고 평소에는 해쉬 함수1만 쓰다가 충돌 시 해쉬 함수2를 써서 새로운 인덱스로 조정하는 방법
2. Close addressing : 해쉬값과 실제 저장된 위치는 다를 수 없다. 충돌이 일어나도 해당 위치에 저장한다. 다만 다른 방법을 써서 기존 값을 버리거나 덮어 씌우는 멍청한 짓은 하지 않는다.
버켓 : 배열의 한 요소가 다시 배열이다. 즉 위처럼 1차원 배열이 아닌 2차원 배열이다. 충돌이 일어나면 다른 위치로 재조정하지 않고 해당 위치에 배열로 쌓는다.
체이닝 : 충돌된 값들을 연결 리스트로 연결한다.
[property]
[method]
insert(key, value) : 주어진 키와 값을 저장한다. 이미 해당 키가 저장되어 있다면 값을 덮어 씌운다..
retrieve(key) : 주어진 키에 해당하는 값을 반환한다. 없으면 undefined를 반환한다.
remove(key) : 주어진 키에 해당하는 값을 삭제하고 값을 반환한다. 없으면 undefined를 반환한다.
resize(newLimit) : 해쉬 테이블의 스토리지 배열을 newLimit으로 리사이징하는 함수이다.
'개념정리' 카테고리의 다른 글
| 9/9 [TIL] OOP(Object Oriented Programming) (0) | 2020.09.09 |
|---|---|
| 9/7[TIL]Graph, Tree, BST (0) | 2020.09.08 |
| 9/3[TIL] Stack & Queue (0) | 2020.09.04 |
| 9/2[TIL] ESLint (0) | 2020.09.03 |
| 9/1[TIL]화살표 함수, this 키워드, call/apply/bind 메소드 (0) | 2020.09.01 |



